[深度实践] 用 Elog 构建双数据库内容系统:自动同步、缓存优化与 CI/CD 集成
2025-9-27|2025-9-27
type
Post
status
Published
date
Sep 27, 2025
slug
250927
summary
这是一篇兼具技术深度与系统思维的实战手记,不仅完整实现了 Elog 多数据库同步与 GitHub Actions 的自动化部署,还涵盖了缓存优化、环境变量管理、CI 触发机制等关键细节,堪称第三代知识管理系统构建的优秀范例。
tags
实用教程
category
动手实践
icon
password
前言
我们之前已经实现了针对单个notion数据库自动触发并执行elog,使用GitHub actions自动备份,我们的目标是使用elog同步多个数据库。
正文
经过查阅项目手册,我们看到了实现这步操作的理论可能性,其中最核心的是在运行elog的时候指定相关参数。简要来说要同步多个知识库,就要为每个知识库配置一套独立的环境变量和配置文件。
对于我而言,我将其设置为
elog-matrixcore.config.js和elog-modulecycle.config.js,里面的配置文件其实大同小异,但是要注意的是环境变量这一栏目要单独分开设置。将多个elog指令同步集成到一个workflow中
从理论角度理解这也并不是一件很复杂的事情,只需要在「拉取语雀/Notion文章」这一步中,依次执行多个
elog sync 命令,每个命令使用不同的配置文件和环境变量文件,就能实现多个知识库的同步。这里我采用package.json 的 scripts.sync来实现,而非直接在workflow中进行运行,代码如下:对应的Workflow代码如下:
复习elog命令行
本地调试可能遇到的dns劫持的问题
首先排查是否是notion集成到问题,查阅后发现同一个 Notion 集成(Integration)是可以被多个数据库复用的。
然后测试访问 Notion API:
发现api能正确返回数据
e,"code":false,"color":"default"},"plain_text":"少年辛苦终身事,莫向光阴惰寸功。","href":null}]...也能正确拿到字段信息。
字段名(name) | 类型(type) | 描述 |
password | rich_text | 密码字段(可能用于加密文章) |
icon | rich_text | 图标字段 |
date | date | 日期字段 |
type | select | 类型字段,有多个选项(Post, Page, Notice, Menu, SubMenu, Config) |
category | select | 分类字段(如:走近生活、璀璨星空、动手实践) |
slug | rich_text | URL Slug |
tags | multi_select | 标签字段,支持多选(如:流动核心、Cadence、热门文章等) |
summary | rich_text | 简介摘要 |
title | title | 标题字段 |
status | select | 状态字段(Published, Invisible, Draft) |
经分析,Notion 的 API 地址 api.notion.com 通常会解析到 Cloudflare 的 CDN,比如 104.16.x.x 或 172.64.x.x,而不是 208.103.161.1。尝试进行调试。 | ㅤ | ㅤ |
1.刷新DNS缓存:
2.增加临时解析测试
3.更换系统DNS
- 打开 系统设置 > 网络 > Wi-Fi > 详情
- 切换到 DNS 标签页
- 添加以下 DNS 服务器:
8.8.8.8(Google DNS)
1.1.1.1(Cloudflare DNS) 然后刷新 DNS 缓存:
专注CLI环境部署
在调试过程中被DNS劫持困扰了很久,但考虑到我们最终是在云CLI的纯净环境中运行,不会有这个顾虑,而且本次调试成功过就行。于是我们直接commit了代码,但是没想到忘记了忽略env文件。以下方法适用于提交了(还没推送
git push):如果已经推送了(
git push ),使用 BFG Repo-Cleaner同时编辑
.gitignore 文件,添加:同时也会触发GitHub 的 Push Protection(推送保护)机制,它阻止你将包含敏感信息(如 Notion Token)的提交推送到仓库,以防止密钥泄露。
在CLI环境中,推荐将敏感信息(如 Notion Token)添加到 GitHub 仓库的
中。
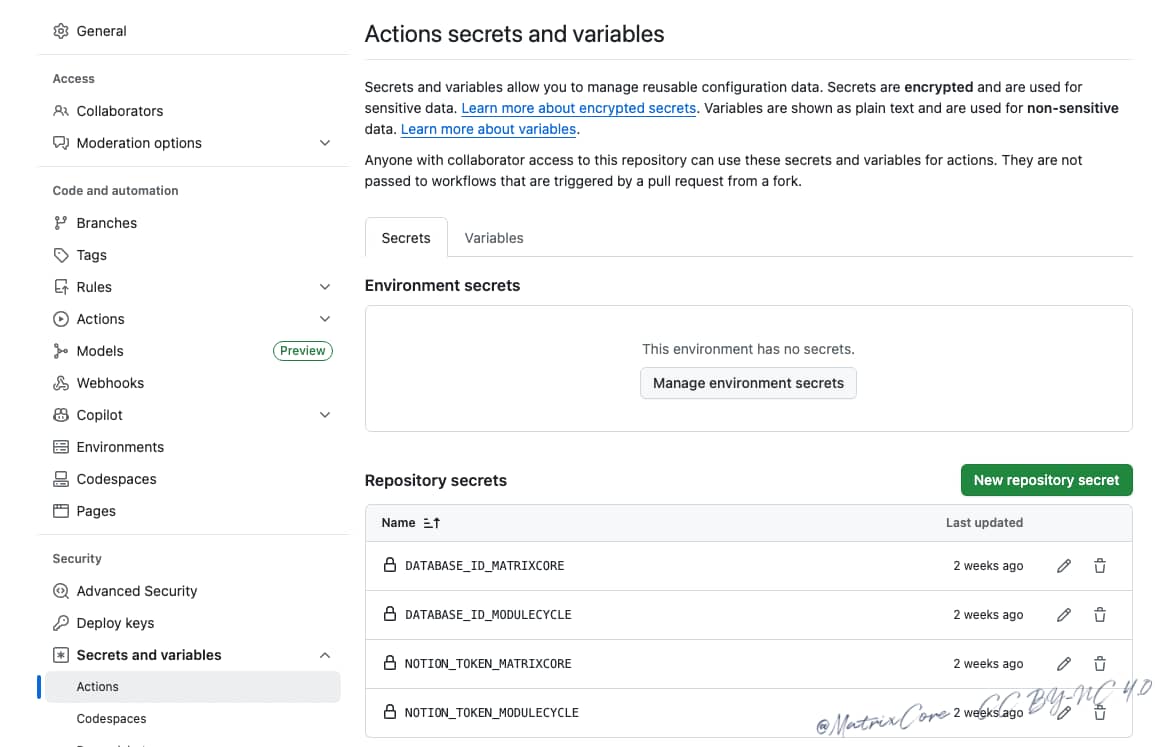
更新workflow配置文件及修改GitHub Actions 中的调用
核心逻辑的修改在上面其实已经介绍了,稍后我会在下面贴出完整代码。另外本地和云CLI在读取环境变量的时候,在加载和运行环境变量的时候也是很不一样的。区别如下:
- 环境变量是通过
env:或secrets注入的系统环境变量。
- 所以 GitHub Actions 中 并不需要(也不会有)本地的
.env文件。
- 在脚本中传了
-env .elog-matrixcore.env,CLI 会尝试读取这个文件,找不到就报错。
将
npm run sync改为npm run sync:ci限于时间和技术能力,我们现在没办法兼容本地和云端,从简化代码复杂度的角度,我们选择仅仅跑通云端即可。然后云CLI和本地CLI还有一个很大的区别,就是环境的区别,那
elog 作为局部依赖(local dependency)不会自动添加到 PATH 中,所以在 GitHub Actions 中无法直接使用 elog。云CLI的缓存机制
在使用像 Elog 这种需要从 Notion 获取数据并生成静态页面的工具时,缓存机制可以极大地提升 CI/CD 的效率。如果你没有做任何缓存处理,CI 每次运行时,都是一个“干净的环境”;本地的
.cache 或 .json 缓存文件不会被保留;所以 Elog 每次都会重新从 Notion 拉取所有数据;导致构建时间变长,尤其是文章多的时候。另外elog项目在自带的workfolw里有一个构建的工作流用于适配不同类型的博客架构,实际上,这个情况我们需要具体情况具体分析,对于我使用的hugo框架而言,构建并不是在workflow这一步做的,而是vercel捕捉到github到修改,自动部署,自动更新blog,所以这一步我不需要构建,所以大家需要根据自己的需要酌情修改。
另外如果想要调用缓存机制,就需要理解:CI/CD 环境(如 GitHub Actions)每次运行都是一个全新的环境,不会自动带上你本地的缓存文件。所以,如果你使用了
--cache 参数,但这个文件在 CI 环境中不存在,就会出现“未识别到缓存”或“找不到文件”的问题。这个时候有两个解决思路:1⃣️将缓存文件提交到 Git 仓库中;2⃣️使用 GitHub Actions 的缓存机制。我们采取里策略2⃣️,GitHub 官方提供了
actions/cache 这个 Action,用来缓存依赖、构建结果、甚至我们要用的 JSON 缓存文件。第一次运行的时候缓存未命中是正常的。说明GitHub Actions 在尝试用配置的
key 和 restore-keys 去找缓存。第一次运行时,仓库中还没有任何缓存被保存过,所以自然就找不到。因此,第一次必须全量同步 Notion 数据库、生成缓存文件配置命令区别解析
在GitHub Actions中显示指定配置更适合CI环境。
对比项 | --module 写法 | --config 写法 |
✅ 配置方式 | 使用默认配置查找机制,可能从 elog.config.js 或 .elogrc 中读取模块配置 | 显式指定某个模块的配置文件 |
✅ 灵活性 | 依赖于主配置文件中的 modules 定义 | 每个模块有独立的配置文件,更易维护和复用 |
✅ 可读性 | 简洁,但模块多时不易区分 | 更清晰,适合多人协作或模块拆分项目 |
✅ 推荐程度 | 适合简单项目或单模块项目 | ✅ 推荐用于多模块项目、CI/CD 场景下更稳定明确 |
elog高级自动化触发原理(基于Notion)
请参见elog的项目文档-持续集成,对于notion而言,是通过notion的集成和自动化监听数据库的属性变化,触发slack通知,通过pipedreams api触发Github actions,所以能想出这个ideas的项目开发者也是个天才,也可以参见我之间写的最佳实践,为什么要提及这个已经实现的事情呢,是为了讲述Pipedreams触发Github actions的关键逻辑,也是本次重构代码踩过的一个大坑,没有定义
workflow_dispatch,所以🔥 GitHub 不会触发这个工作流 —— 这是预期行为。还有一行关键代码,当外部发送了一个 repository_dispatch 请求,带上 event_type=deploy,GitHub 就会触发这个 workflow,这也是elog项目需要特殊注意的地方,否则这个工作流不会触发。提交和推送代码分开执行
错误使用案例:
问题解析:
uses: 和 run: 不能同时出现在一个 step 中;uses: 是调用一个 Action;run: 是执行 Shell 命令。正确做法:
实现效果
通过Notion+NotionNext搭配的方式,两种数据库创作不同风格和类目的文章,分别指向:matrixcore.love和matrixcore.top。通过elog的多数据库同步的能力,实现文档的开源和双重备份及开放式访问的渲染,并结合git的稀疏检出及obsidian强大的双链功能,最终实现数据的回归反馈和循环迭代,完成输入输出的闭环,构建第三代CMS的健壮的知识管理系统。
总结
有的时候我们难免迷路,就像生命本身1/2.5亿的传奇,我们在感叹人本身的坚韧的同时,应焕发出其原有的生命张力,也应感谢前人铺就的锦绣长廊,因为每一次的超越,都是站在巨人的肩膀上。
Loading...
- About

Bookmark
我说你是人间的四月天。
《你是人间的四月天》
林徽因